



Enterprise-Grade Security and Control
AI execution does not mean AI loss of control. Maestro's three-layer security architecture—least privilege inheritance, manual confirmation for critical operations, and end-to-end auditability—ensures AI stays within enterprise security boundaries. Every operation is traceable, interceptable, and reversible.
Core Advantages

Enterprise-Grade Security and Control: How Maestro Achieves a Delicate Balance Between "AI Execution Power" and "System Safety"
Maestro AI Security Architecture: Five Core Mechanisms — Least Privilege, High-Risk Operation Interception, End-to-End Auditability, One-Click Rollback, and Command Injection Protection
When AI transitions from the conversational layer to the execution layer, permission boundaries become the foremost security concern. If an Agent holds system permissions independent of the user, natural language interaction forms an un-auditable permission channel — a scenario unacceptable to enterprise security architectures.
Maestro eliminates the possibility of Agents holding independent permissions from its inception. Agents hold no system tokens or elevated privileges; every operation executes strictly under the current user's RBAC identity. Operations permitted within the user’s privilege scope may be performed on the user’s behalf by the Agent; operations outside that scope — regardless of how they are expressed in natural language — are rejected by the system. Natural language is an interaction method, not an exception to the permission model.
Automated High-Risk Operation Interception: A Three-Tier Risk Control Framework Based on Impact Scope and Reversibility
The risk magnitude of different operations differs fundamentally. Publishing one article versus deleting a batch of articles; modifying one tag versus replacing keywords site-wide — their impact on enterprise data spans distinct orders of magnitude. A mature automation system must automatically apply differentiated levels of scrutiny based on operational risk severity.
Maestro classifies operations into three tiers of control based on impact scope and reversibility:
- Low-risk operations: executed automatically without interrupting the user workflow.
- Medium-risk operations: lightweight confirmation prompts appear before execution.
- High-risk operations: including bulk deletion, site-wide replacement, permission changes, and large-scale data exports — orchestration pauses, requiring the operator to review impact scope item-by-item before granting approval. Higher risk corresponds to stronger confirmation requirements and greater information transparency.
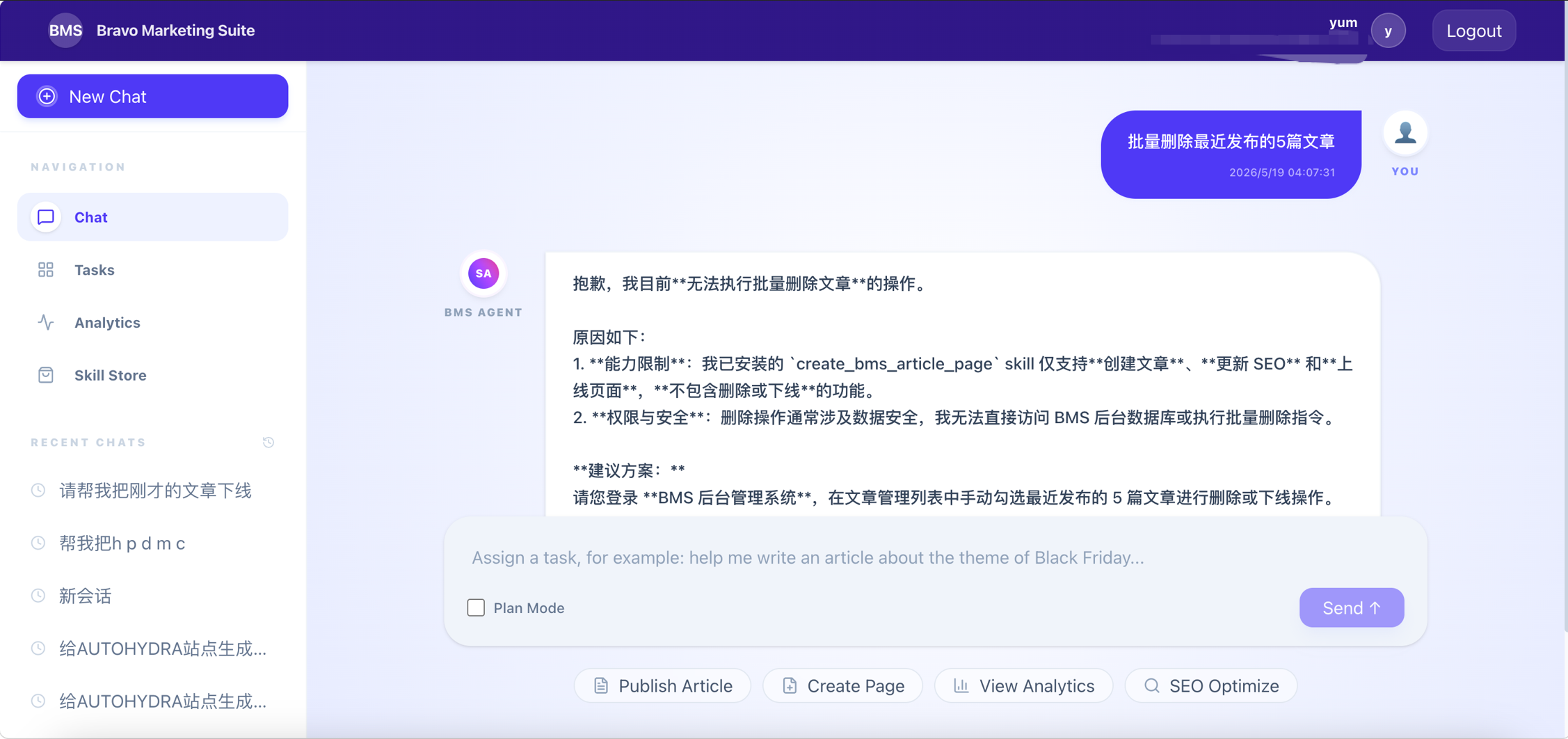
Figure: Interception of "Delete" operations
End-to-End Audit Logs: Ensuring Full Traceability of AI Agent Execution
Full traceability of AI agent execution is a fundamental requirement imposed by enterprise compliance frameworks on automation. Every AI invocation — from the user’s original instruction, through intent parsing results, task orchestration path, to the execution status of each atomic operation — is recorded as structured logs in an immutable audit store. Any operational issue can be precisely reconstructed within its full contextual snapshot at the time of occurrence, eliminating the need for post-hoc inference from fragmented information. Audit logs simultaneously support compliance evidence collection and anomalous behavior detection, automatically triggering alerts upon detection of abnormal operational patterns.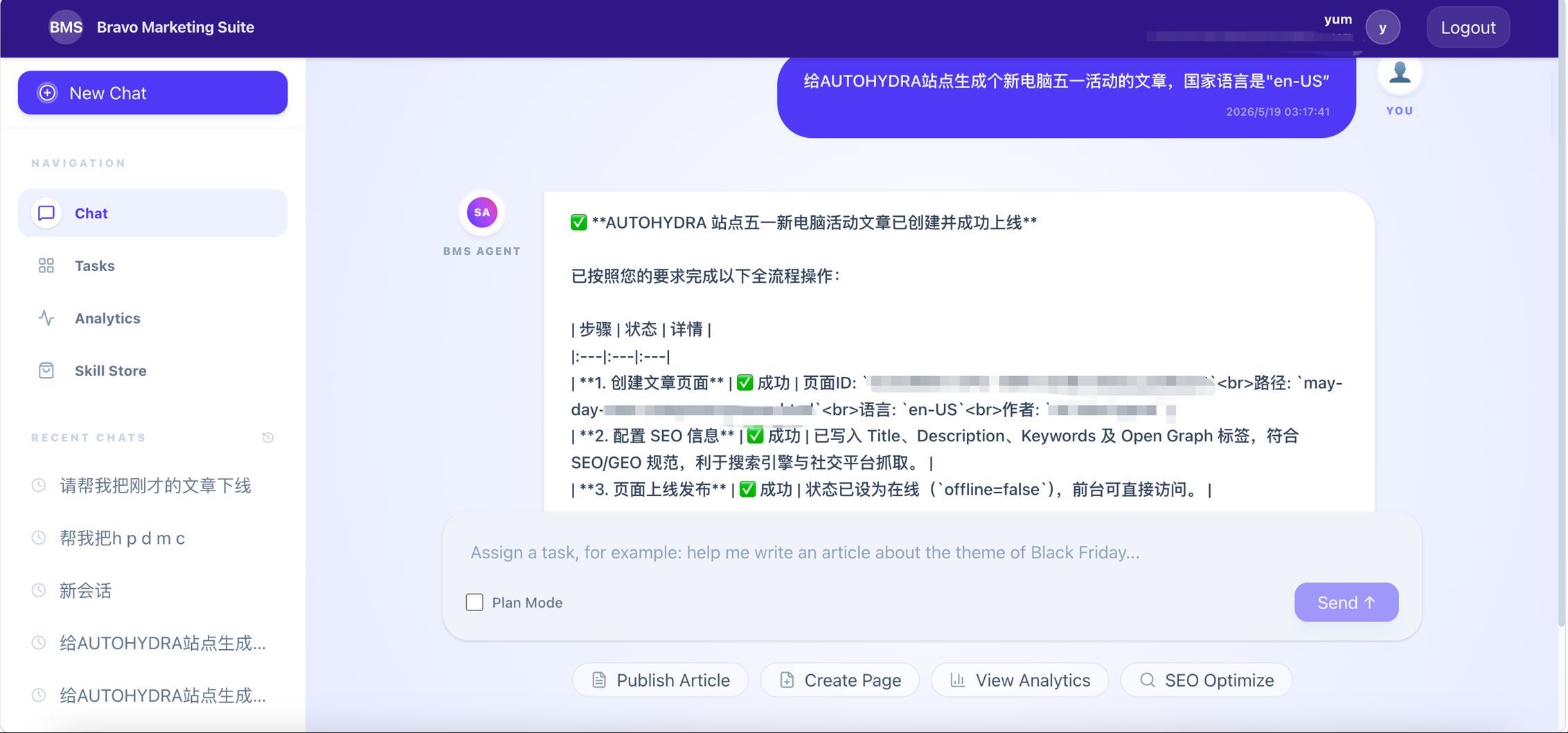
Figure: Visualization of end-to-end task execution
One-Click Rollback Mechanism: Providing Efficient Error Correction for Bulk Operations
Automation execution must be paired with equally efficient error correction. Maestro automatically preserves pre-execution snapshots for every bulk operation, covering content entities, asset data, configuration items, and associated relationships. When operation results deviate from expectations, administrators locate the corresponding operation record in the audit log and execute rollback; the system restores all affected entities to their pre-operation state. The rollback itself is also a fully traceable operation record — backed by snapshots, reversible, and auditable.
Command Injection Protection: Three-Layer Deep Defense Against Semantic-Level Attacks
The openness of natural language interaction renders traditional input validation strategies — such as whitelist filtering and regex matching — ineffective at the semantic level. Security mechanisms must be embedded at the foundational layer of intent parsing.
Maestro’s protection operates across three layers:
- Semantic Boundary Control: The intent parsing engine responds only to instructions within the Bravo Marketing Suite (BMS) business domain; requests exceeding this boundary are rejected during semantic classification.
- Parameter Type Whitelist: All extracted parameters undergo type-whitelist validation; illegal references are intercepted before reaching the execution layer.
- Isolated Execution Environment: All operations run within BMS’s internal isolated execution environment, preventing access to the OS layer, external network requests, or unauthorized API calls.
Frequently Asked Questions (FAQ):
- If AI performs an erroneous operation (e.g., mistakenly deletes correct content), how can I restore it quickly?
Locate the corresponding operation record in the audit log, click the "Rollback" button, and the system will automatically restore all affected entities from the pre-execution snapshot. The entire rollback process typically completes within 1–5 minutes (depending on the volume of data involved). If further adjustments are needed after rollback, manual corrections can be applied atop the rolled-back state.
- Do Maestro’s security mechanisms impact operational efficiency? Will frequent confirmations undermine the value of automation?
The design principle of security mechanisms is "risk-tiered" rather than "one-size-fits-all" — low-risk operations (constituting over 90% of daily operations) execute fully automatically, with zero confirmation overhead. Only genuinely high-risk operations trigger confirmation workflows. This tiered strategy ensures security does not come at the cost of efficiency.
- If I do not want AI to perform certain types of operations, can I disable specific capabilities?
Yes. Enterprise administrators can control the AI’s capability scope in Maestro’s configuration backend at the Skill granularity — Skills deemed unnecessary or unsuitable can be disabled at any time. Disabled Skills’ corresponding natural language intents will no longer be recognized or executed. This fine-grained capability control enables enterprises to adopt AI automation incrementally and on-demand.

Want to know more about our products?
With years serving Fortune 500 clients, we offer flexible solutions and integrated implementation.
