



AI Integration and Empowerment for DAM
Integrate AI-powered content creation, multimodal search, compliance security inspection, and omnichannel output to enable zero-threshold, efficient content production—helping enterprises achieve single-source, multi-channel content utilization, cost reduction, and efficiency enhancement.
Core Advantages



AI-Powered Intelligent Digital Asset Management Platform
BMS Digital Experience Platform , integrates three core AI capabilities: online AI image editing, parametric design, and AI video generation. Supports natural-language-driven image re-rendering and batch intelligent processing—non-designers can produce professional-grade visual content in just 30 seconds. The system provides an intelligent tagging framework and AI-powered multimodal search, enabling sub-second precise retrieval across 200+ file formats. An embedded AI content security engine automatically identifies font copyright issues, sensitive elements, and infringement risks, ensuring end-to-end compliance. Through intelligent format-adaptive output, a single creative effort generates asset packages optimized for WeChat Mini Programs, Amazon, overseas social media, and other channels—truly realizing the "one-source, multi-use" enterprise content hub solution to reduce costs, improve efficiency, and usher in a new era of scalable content operations driven by generative AI tools.
Key Advantages
1. AI Preset Parametric Editing: Standardized Visual Output—Professional Images in Seconds, No Design Skills Required
For high-frequency e-commerce and marketing scenarios, the system includes a built-in industry-specific parameter template library (e.g., " product white-background image + branded watermark + standardized dimensions "). Users simply upload raw assets and adjust parameters—including watermark content, position, opacity, background color, and output dimensions—via an intuitive visual panel; AI then automatically performs professional-grade processing. This "fill-in-the-blank" editing approach completely eliminates dependence on Photoshop. Marketing personnel without design expertise can efficiently generate large batches of brand-compliant visual content, reducing per-image processing time from 30 minutes to 30 seconds.
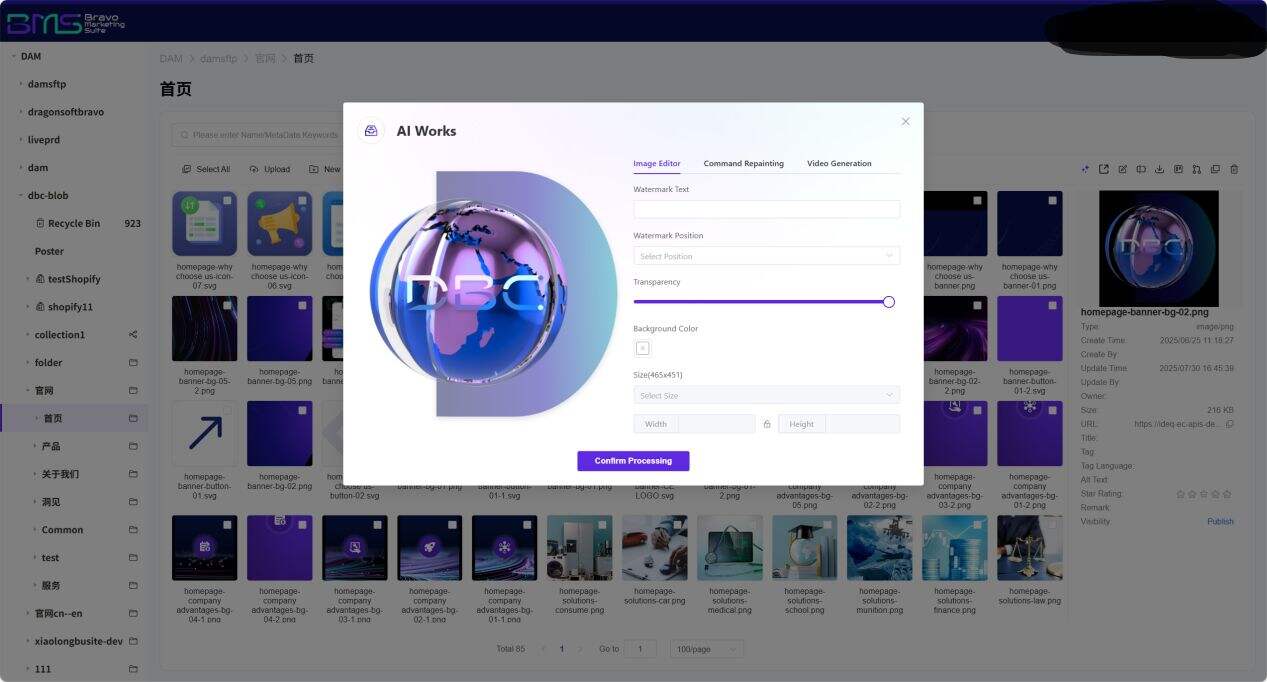
2. AI Free-Form Instruction Repainting: Creativity Driven by Natural Language—What You Imagine Is What You Get
Beyond traditional editing tool limitations, the system supports Command Repainting. Users describe creative requirements in natural language (e.g., " replace background with a tech-inspired blue gradient and add lighting effects "); AI parses the instruction and generates results—supporting iterative, command-based interactive refinement. This generative editing capability empowers non-professionals to achieve professional retouching quality, while retaining manual fine-tuning options to enable efficient “AI generation + human optimization” collaboration, dramatically lowering the barrier to creative visual production.
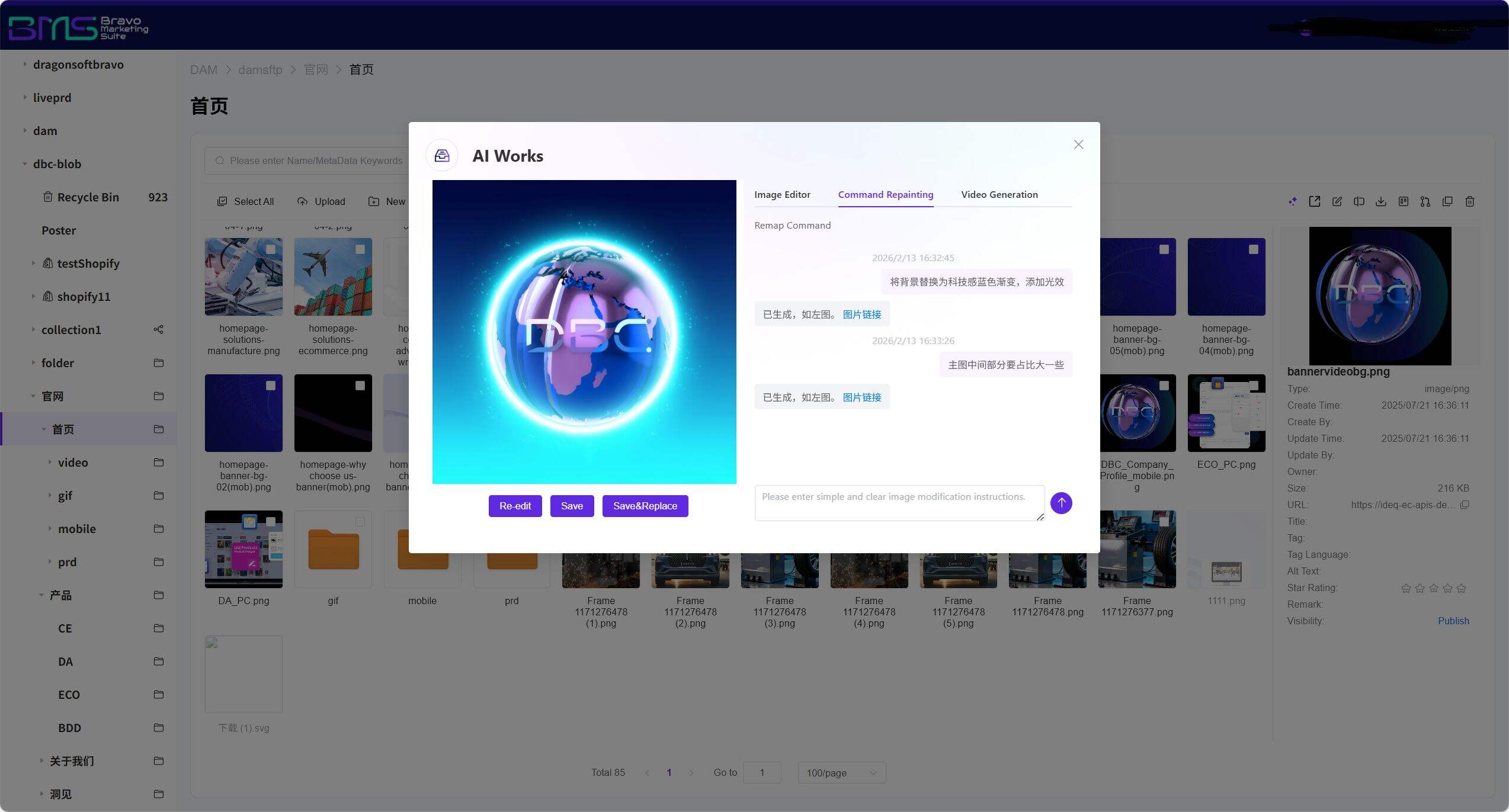
3. AI Video Generation: Instant Dynamic Conversion of Static Assets—Unlocking Multimedia Formats
Leveraging the Video Generation engine, the system automatically converts static images into marketing short videos. AI intelligently detects the primary subject (e.g., product or person), automatically matches transition animations, background music, and subtitle styles per instruction, and one-click generates dynamic video assets—including product showcase animations, brand story reels, and social-media shorts—bringing static content to life. No video editing software required: images stored within DAM can directly spawn video derivatives, implementing a "one-source, multi-use" asset reuse strategy to meet diverse content demands of the short-video era.
4. Intelligent Format-Adaptive Output—Cross-Channel Distribution in One Click
Assets processed by AI support intelligent multi-spec export. The system automatically selects optimal resolution, color mode, and file format based on target channel (e.g., WeChat Mini Programs, e-commerce apps, overseas social media, offline printing). Batch output rules can be preconfigured (e.g., " Amazon main image: 3000×3000px white background + detail page landscape video: 16:9 "); a single operation generates fully channel-adapted asset packages, enabling "one AI creation, automatic full-channel adaptation" for scalable content operations.
5. AI Content Security Inspection
Upon upload, content undergoes comprehensive AI-driven compliance scanning covering unauthorized font identification, competitor element detection, sensitive portrait screening, intelligent keyword filtering, image content safety review, religious/cultural compliance verification, and copyright material & infringement risk assessment. Based on risk severity, the system automatically triggers interventions—including direct blocking, manual review, or content anonymization—ensuring end-to-end compliance from upload to publication and minimizing operational and legal risks.
6. Intelligent Tagging Framework
AI-powered auto-tagging and dynamic knowledge graphs empower assets to “speak for themselves,” enabling deep association and intelligent recommendations.
• Dynamic Knowledge Graph: Tags form a "product-scene-style-channel" relational network; related tags are intelligently recommended during search
• Continuous Learning Mechanism: Analyzes user behavior to automatically optimize tag weights, building enterprise-specific visual semantic understanding
• Multilingual Tagging: Built-in multilingual processing enables intelligent tagging in major languages including Chinese and English
Accuracy Metrics:
AI tag accuracy in general scenarios reaches 94%; industry-specific models can be rapidly customized using only 50–100 sample images.
Leveraging computer vision and NLP technologies, the system automatically identifies key information—including content, scene, people, and emotion—during asset ingestion and generates precise tags. These tags are not isolated but constitute a dynamic knowledge graph that logically connects seemingly unrelated assets. When searching for a picture tagged “summer beach,” the system not only returns matching results but also intelligently recommends related assets such as “beach activity videos,” “summer marketing copy,” etc., maximizing asset reuse value.
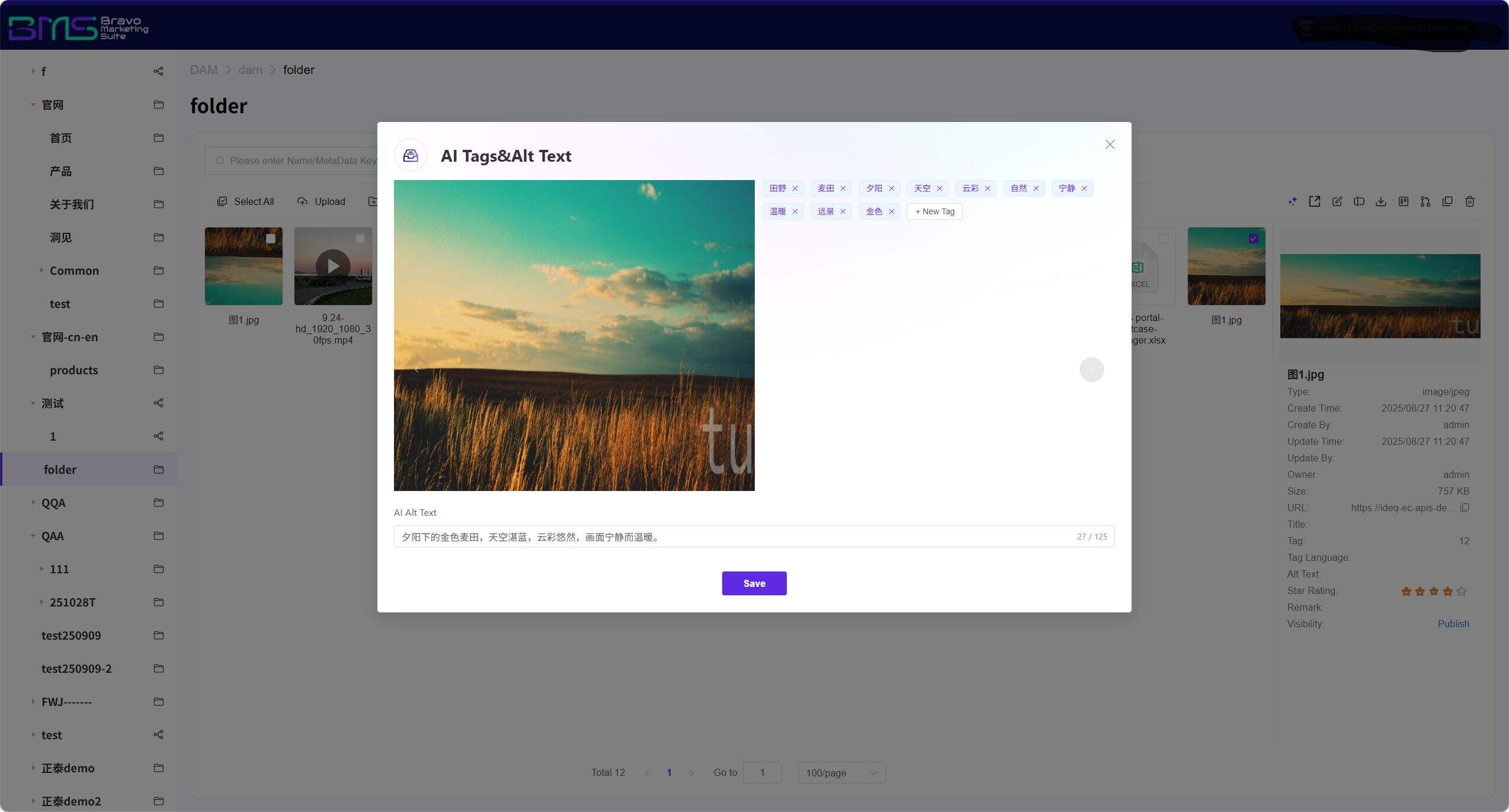
7. AI Multimodal Search
Core Capabilities:
• Full-text Semantic Search: Uses NLP to understand document content, video subtitles, and printed text in images—breaking free from filename-only constraints
• Image-to-Image / Video-to-Asset Search: Extracts color, composition, and stylistic features via computer vision; users may upload reference images to find visually similar assets
• Voice Command Search: Mobile support for natural-language voice input; ASR engine automatically converts speech into structured queries
• Cross-Modal Semantic Association: Input emotional keywords (e.g., " joyful, futuristic ") to simultaneously retrieve matching ambient music, video clips, and graphic assets
Our DAM system transcends traditional keyword-only search limitations. Using AI multimodal technology, it unifies retrieval across text, images, videos, and audio. Whether users input a descriptive phrase, upload a reference image, or speak a voice command, the system precisely interprets intent and locates targets within the vast asset library in seconds. This reduces asset discovery time from hours to seconds—and empowers non-specialists to navigate complex repositories effortlessly, significantly boosting team-wide productivity. Say goodbye to inefficient “needle-in-a-haystack” searches.
Frequently Asked Questions (FAQ)
Q1: Which input formats does AI video generation support? What assets do I need to prepare?
A1: Supports JPG, PNG, WebP, and other static image formats as input. The system automatically identifies the main subject and recommends animation templates. Existing assets already in the DAM library can be directly invoked—no additional preparation required. Generated video duration ranges from 15–60 seconds, with maximum resolution up to 4K, meeting mainstream social media platform requirements.
Q2: How accurate is AI’s understanding of free-form instructions? Does it support multilingual commands?
A2: Built upon a multimodal large language model, the system supports natural-language instructions in multiple languages. It has been specially optimized for vertical domains like e-commerce and industrial products, achieving over 95% recognition accuracy for common commands such as “change background style,” “add light/shadow effects,” and “remove clutter.” Complex instructions support stepwise decomposition and preview confirmation to ensure outputs meet expectations.
Q3: Can preset parametric editing templates be customized and saved?
A3: Yes. Enterprise administrators can save frequently used parameter combinations (e.g., specific watermark style + fixed dimensions + branded background color) as enterprise-exclusive templates, accessible to team members with one click. Template usage permissions can also be configured to enforce strict adherence to brand visual standards at scale.
Q4: Does AI editing compress file quality? How is print-grade precision ensured?
A4: Employs intelligent layered rendering: optimized versions load during preview for smooth interaction, while exports support selection of either “original quality” or “print-grade (300 dpi)” modes. The system re-renders from original high-resolution files to guarantee crisp detail—even when enlarged for physical printing.
Q5: Who owns the copyright to AI-generated content? Is commercial use safe?
A5: All AI-edited or AI-generated content derived from users’ proprietary assets remains fully owned by the user’s enterprise. The system uses compliant training data and rigorous filtering mechanisms to ensure zero third-party copyright risk in generated outputs and provides commercial licensing certificates to satisfy enterprise compliance audits.
Q6: Which file formats does DAM’s AI multimodal search support? What exactly does “multimodal” mean?
A6: Supports 200+ formats, including JPG/PNG/PSD/AI (images), MP4/MOV/AVI (videos), PDF/DOCX/PPTX (documents), OBJ/FBX (3D models), WAV/MP3 (audio). “Multimodal” means the system simultaneously understands text, visual, and audio modalities: text queries can retrieve video content; uploaded images can find stylistically similar assets; voice commands can locate specific assets. Special formats may be extended via custom parsers.

Want to know more about our products?
With years serving Fortune 500 clients, we offer flexible solutions and integrated implementation.
