



企业级安全可控
AI 执行不等于 AI 失控。Maestro 以"权限最小化继承 + 关键操作人工确认 + 全程审计追溯"三层安全架构,确保 AI 的执行力始终在企业安全边界之内。每一个操作都可追溯、可拦截、可回滚。
核心优势

企业级安全可控:Maestro 如何在"AI 执行力"与"系统安全性"之间实现精妙平衡
Maestro AI 安全架构五大核心机制:权限最小化、高危拦截、全链路审计、一键回滚与指令注入防护
当 AI 从对话层进入执行层,权限边界成为首要的安全命题。Agent 若持有独立于用户的系统权限,自然语言交互便构成一条不可审计的权限通道——这是企业安全架构无法接受的。
Maestro 从设计之初即排除了 Agent 独立权限的可能性。Agent 不持有任何形式的系统令牌或提升权限,每一次操作均严格以当前用户的 RBAC 身份执行。用户权限范围内可执行的操作,Agent 可代为执行;用户权限范围外的操作,无论以何种自然语言表达,均被系统拒绝。自然语言是一种交互方式,不是权限体系的例外。
高危操作自动拦截机制:基于影响范围与可逆性的三级风控体系
不同操作的风险量级存在本质差异。发布一篇文章与删除一批文章,修改一个标签与全站替换关键词——它们对企业数据的影响面处于不同数量级。成熟的自动化系统应当对不同风险等级的操作自动施加不同强度的审慎控制。
Maestro 将操作按影响范围与可逆程度划分为三级管控:
- 低风险操作:自动执行,不中断用户工作流。
- 中风险操作:执行前以轻量提示请求确认。
- 高风险操作:包括批量删除、全站替换、权限变更、大规模数据导出等,编排暂停,要求操作者逐项审核影响面后再决定是否放行。风险越高,确认的力度和信息透明度同步上升。
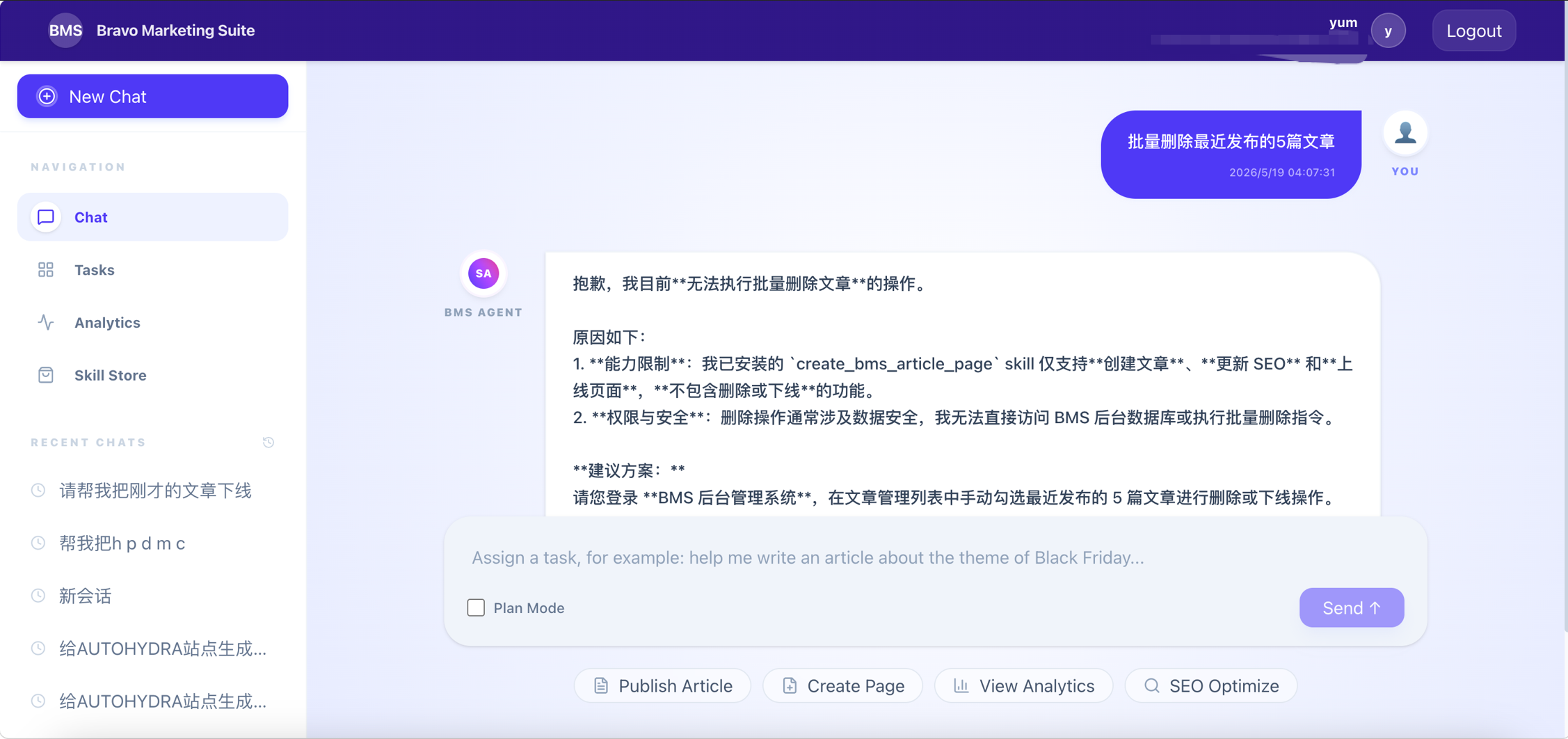
图:“删除”操作拦截
全链路审计日志:实现 AI 代理执行的完整可追溯性
AI 代理执行的可追溯性是企业合规体系对自动化提出的基本要求。每一次 AI 调用——从用户输入的原始指令,到意图解析结果,到任务编排路径,到每一步原子操作的执行状态——均以结构化日志写入不可篡改的审计存储。任何操作问题可被精确还原至当时的完整上下文,无需事后通过碎片化信息拼接推断。审计日志同时支持合规举证与异常行为检测,在异常操作模式出现时自动触发告警。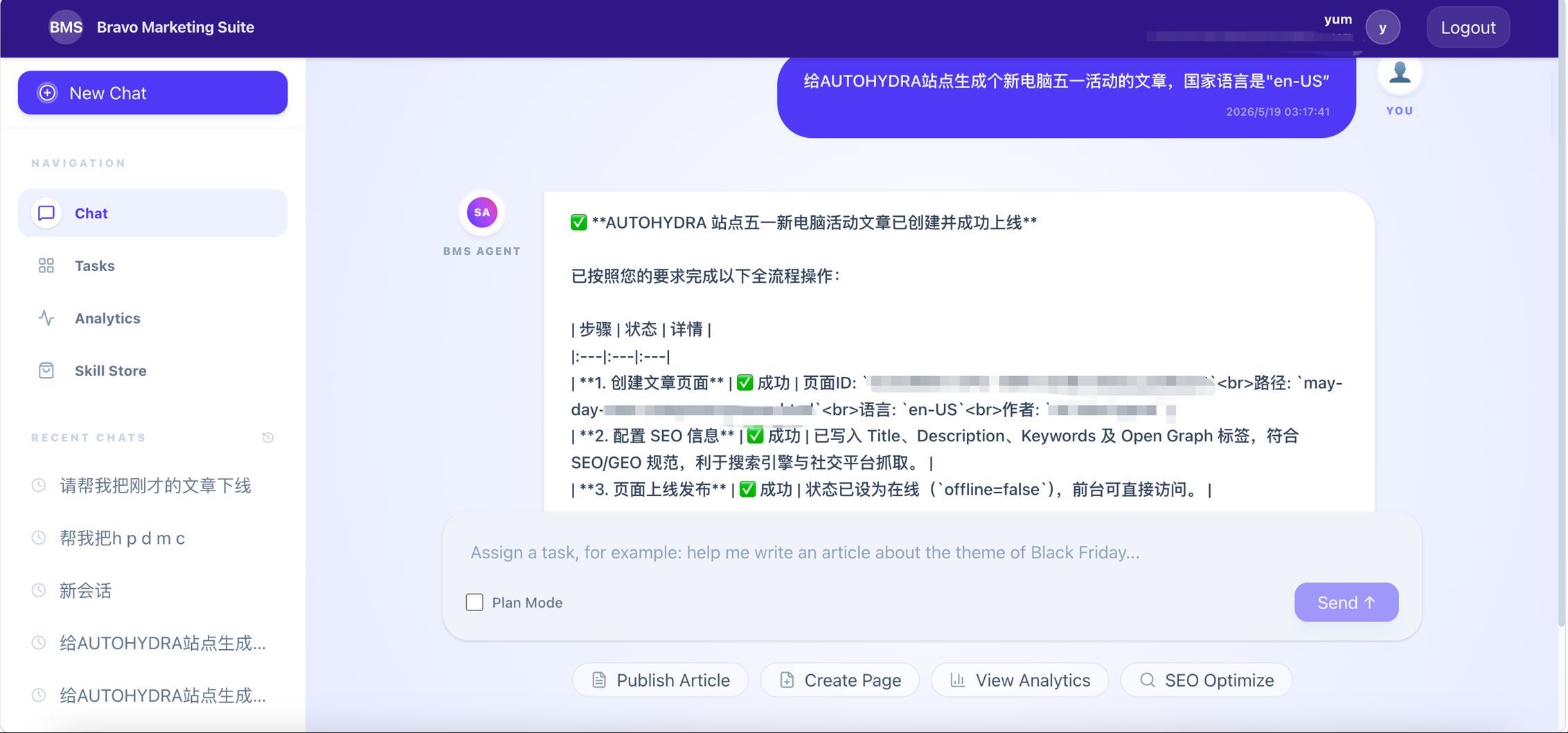
图:全链路任务执行可视化
一键回滚机制:为批量操作提供高效纠错保障
自动化执行需要搭配同等效率的纠错手段。Maestro 为每一次批量操作自动保留操作前快照,覆盖内容实体、资产数据、配置项及关联关系。当操作结果不符合预期时,管理员在审计日志中定位对应操作记录,执行回滚,系统将所有受影响实体恢复至操作前状态。回滚本身也是一条可追溯的操作记录,有快照、可逆、可审计。
指令注入防护:三层纵深防御抵御语义层面攻击
自然语言交互的开放性意味着传统的输入校验策略——白名单过滤、正则匹配——在语义层面失效。安全机制必须内置于意图解析的底层。
Maestro 的防护同时作用于三个层面:
- 语义边界控制:意图解析引擎仅在 BMS 业务范围内响应指令,超出边界的请求在语义分类阶段即被拒止。
- 参数类型白名单:所有提取的参数经类型白名单校验,非法引用在进入执行层前被拦截。
- 隔离执行环境:全部操作运行于 BMS 内部隔离执行环境,无法触达操作系统层、发起外部网络请求或调用未授权接口。
常见问题解答(FAQ):
- 如果 AI 执行了错误操作(如误删了正确的内容),我如何快速恢复?
在审计日志中找到该次操作记录,点击“回滚”按钮,系统将自动恢复操作前快照中的所有受影响实体。整个回滚过程通常在 1–5 分钟内完成(取决于操作涉及的数据量)。如果回滚后仍需进一步调整,可在回滚基础上手动修正。
- Maestro 的安全机制是否影响操作效率?频繁确认会不会让自动化失去意义?
安全机制的设计原则是“风险分级”而非“一刀切”——低风险操作(占日常运营的 90% 以上)完全自动执行,零确认门槛。只有真正高风险的操作才会触发确认流程。这种分级策略确保了安全不成为效率的代价。
- 如果我不想让 AI 执行某类操作,可以禁用特定能力吗?
可以。企业管理员可以在 Maestro 配置后台以 Skill 为粒度控制 AI 的能力范围——对于不需要或不适用的 Skill,可随时禁用。被禁用的 Skill 对应的自然语言意图将不再被识别和执行。这种细粒度的能力控制确保企业可以按需、逐步地采纳 AI 自动化。

