



全域上下文感知
Maestro 与 BMS DXP 共享底层数据总线,能够获取用户角色、权限范围、历史操作记录及全平台业务数据。每一次交互都建立在"谁在问、在什么数据范围内、面对什么业务背景"的精准理解之上,而非无差别的通用应答。
核心优势


全域上下文感知:Maestro 如何成为真正"懂业务"的 AI
一、用户身份与权限感知
提问者身份决定了问题的正确答案应落在哪个数据维度、聚合层级与决策视角上。通用 AI 对话以“提问者身份未知”为前提,回应的精确性必然受限于这一关键信息的缺失。
Maestro Agent 继承 BMS DXP 的用户体系与 RBAC 权限模型。对话启动时,Agent 已自动获知用户的角色身份、数据权限边界与组织归属,查询范围即时收敛至权限内数据,回应口径精准匹配角色视角。身份信息不是用户每次提问时需重复声明的附加参数,而是 Agent 在对话发生前已纳入计算的底层变量。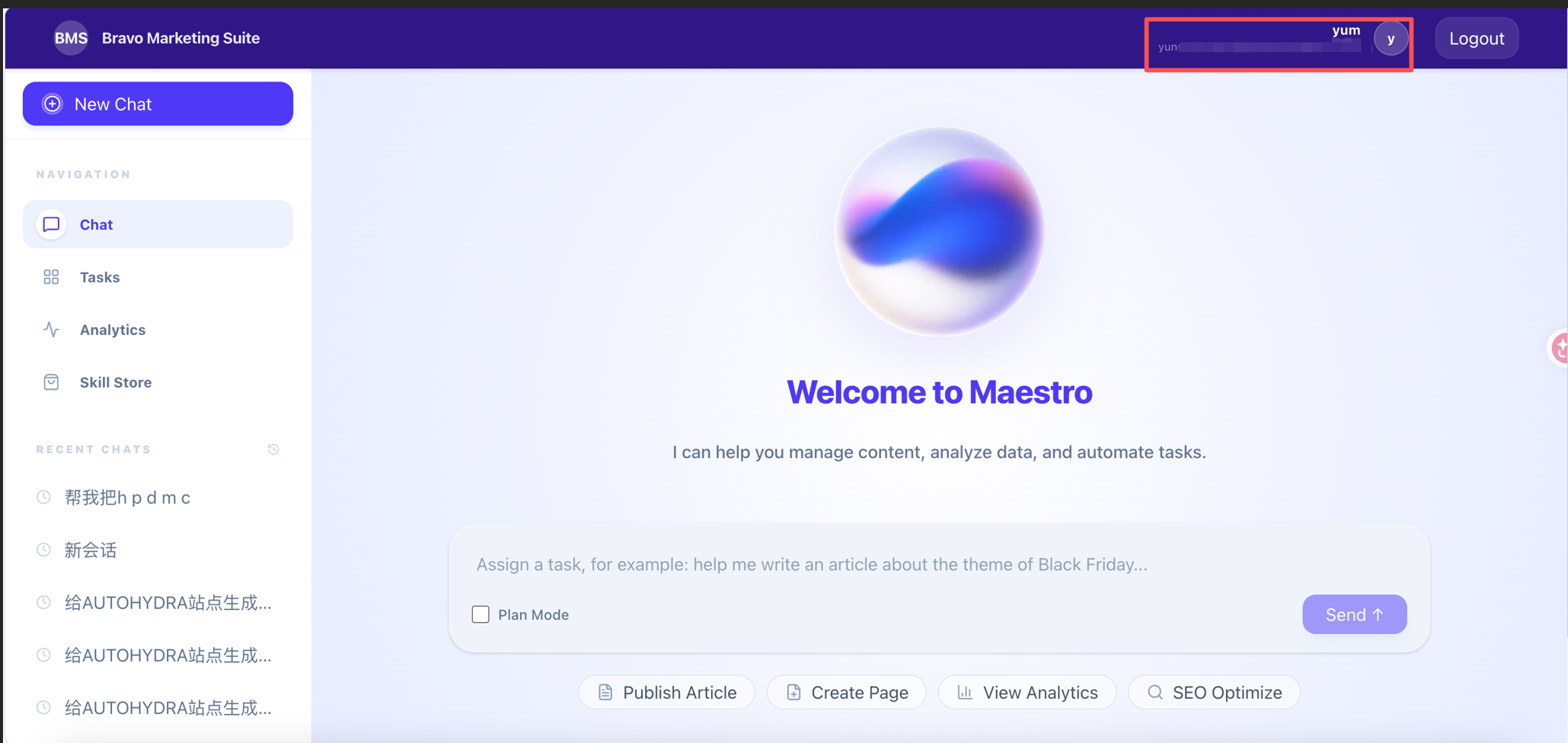
图:用户统一身份认证
二、业务数据上下文感知
自然语言指令中普遍存在指代与省略,这是人类沟通效率的来源,却是 AI 理解的障碍。当指令中出现的业务实体——内容条目、数字资产、商品 SKU、站点配置——未被显式声明完整路径时,Agent 需具备从数据层直接解析这些指代的能力,而非要求用户将每一处省略展开为冗长描述。
Maestro 通过接入 BMS 数据总线,实时获取指令中涉及的业务实体及其关联关系。这些实体在 BMS 内部已有完整的映射与拓扑记录,Agent 直接读取而非从零推断。业务上下文不是对话中逐步教授的知识,而是从企业数据层直接获取的已知信息。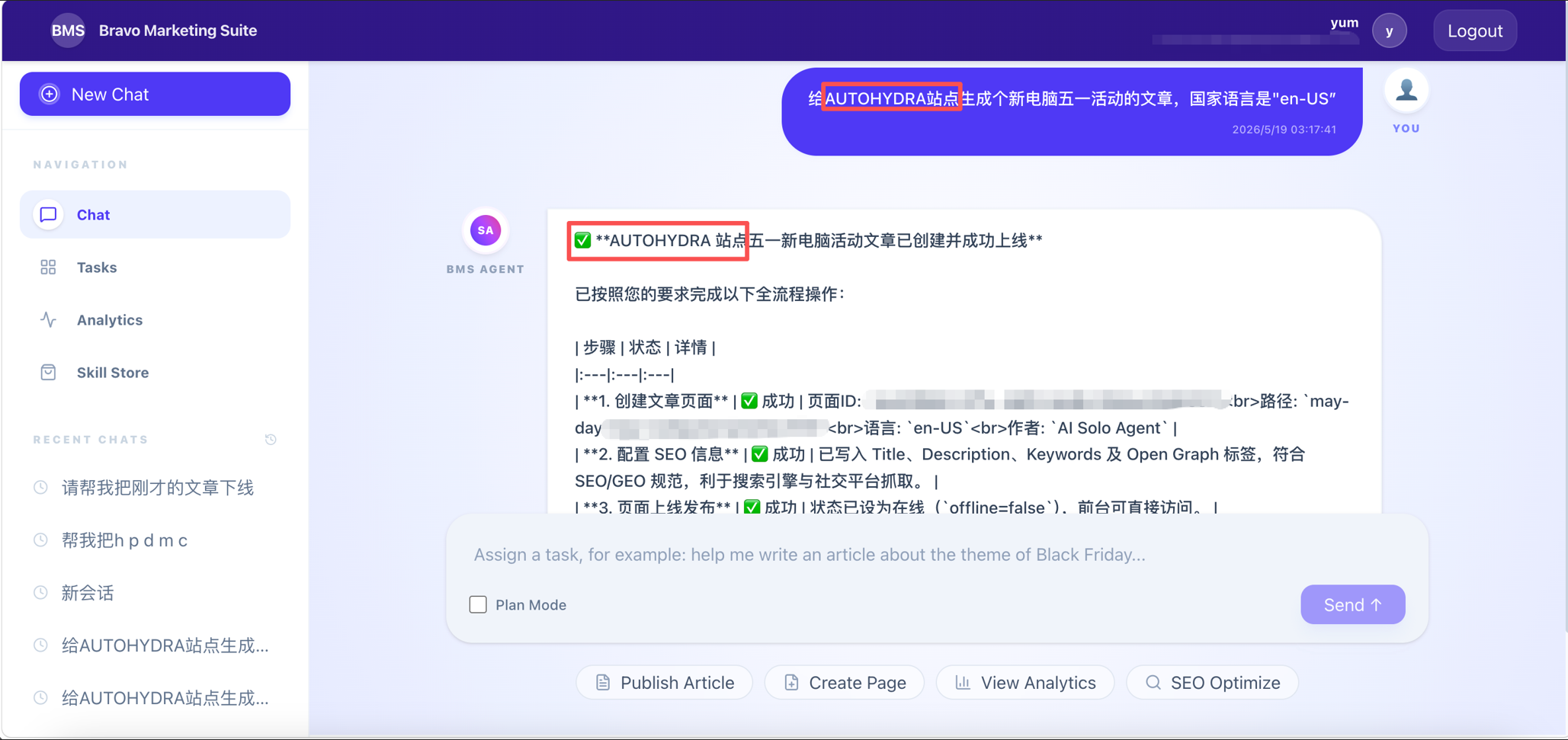
图:业务站点识别
三、历史交互学习
用户与 Maestro 的每一次交互都在为系统提供关于该用户工作模式的增量信息。指令类型分布、操作时序规律、参数默认偏好——这些行为特征在日常使用中被持续采集和结构化,形成对该用户运营节奏和决策习惯的渐近拟合。高频任务的执行路径被智能缩短,常用参数组合被前置推荐,周期性操作在临近时点被预加载。学习效果随交互频次递增,无需用户离开工作流进行偏好设置或规则配置。
四、多角色自适应
职责的复合性是企业运营的常态。传统系统将角色设计为需要手动切换的独立工作台,切换越频繁,割裂感越强。
Maestro 采用角色叠加而非角色切换的方式处理多角色场景。用户无需在交互前声明当前角色,Agent 综合呈现各角色对应视角的信息与建议,并以标签清晰区分来源。用户也可随时手动锁定某一角色视角,聚焦特定业务维度。
五、业务术语理解
每家企业都会沉淀出一套独有的内部语言——产品代号、项目命名、流程简称。这些术语在组织内部沟通中高效精准,但对新人和外部系统构成理解门槛。Maestro 通过双通道吸收企业术语:其一,在日常交互中通过上下文动态推断术语含义,并建立与 BMS 实体的语义映射;其二,管理员可在后台维护关键术语对照表,确保核心业务概念被准确识别。用户始终以内部惯用的表达方式工作,Agent 在后台无缝完成语义映射。
常见问题(FAQ)
- Q1:Maestro 如何区分不同用户的身份和权限?
A1:Maestro 直接继承 BMS DXP 的用户体系和 RBAC 权限模型。用户登录时,Agent 通过 SSO 即时获取其角色、权限范围和组织归属信息。所有后续对话均严格限定在用户可见的数据边界内,不会因自然语言交互而绕过权限限制。
- Q2:业务术语如何让 Maestro 学会?是自动的还是需要配置的?
A2:两种路径并行。一是持续学习——用户在对话中自然使用的业务术语,Agent 通过上下文推断其含义并记忆;二是主动配置——企业管理员可在后台维护术语映射表,确保关键业务概念被准确理解。
- Q3:如果用户换了岗位或权限变更,Maestro 多久能适配?
A3:权限变更在 BMS 用户系统中生效后,Maestro 即时同步。历史学习数据(如指令偏好、高频任务)可在管理员协助下迁移至新角色,或按需清除后重新学习。
- Q5:共享数据总线意味着 Maestro 能看到所有 BMS 数据吗?
A5:不是。数据总线的访问受权限模型约束——Maestro 始终以当前用户的 RBAC 身份读取数据。用户能访问什么数据,Agent 就能读取什么数据;用户无权访问的数据,Agent 同样无法触及。数据总线共享的是接口通路,不是权限豁免。

